Two-Dimensional VLOOKUP in Pandas¶
One thing that I particularly enjoy about teaching Pandas is showing people how much better it is than Excel. Every so often I get a question about how to do something in Pandas (that is easy in Excel) that requires me to think for a few minutes here is an example of such a question. My hope is that you find this tutorial informative if you have any questions or spot any mistakes feel free to reachout at jason@jbedford.net
Question: Given two tables as shown below
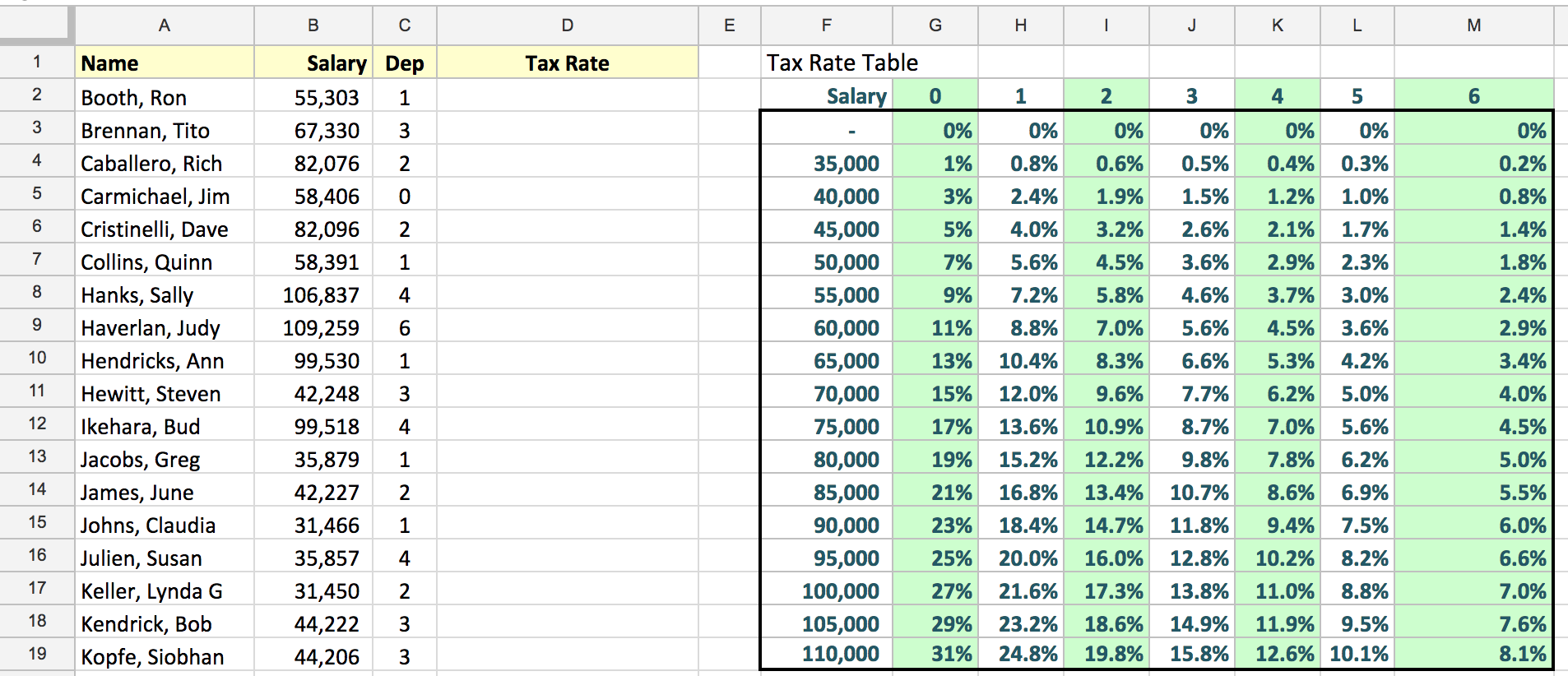
Fill in the column ‘Tax Rate’ given the data in columns 'Salary' and 'Dep' (short for number of dependence) using the the data in the Tax Rate Table. Note Salary should be classified as the nearest number below the actual salary and Dep should be an exact match.
Solution in Excell¶
In excel you would click on cell D2 and enter the following
=vlookup(B2,F:M,C2+2)
Then drag this down the rows of column 'D' to fill in the values.
Solution in Pandas¶
I'll cut to the chase and show you how I ended up solving this problem. At the end I'll discuss some other ideas I had. Let's get started by importing the data which I have made into two CSVs.
import pandas as pd
df_employees = pd.read_csv('hr_employee_data.csv')
df_employees.head()
df_tax = pd.read_csv('tax_table.csv')
df_tax.head()
First I defied a tax bracket from the salary column in df_tax (This may not make sense at the moment but hang on I'll explain at the end)
df_tax_braket = pd.DataFrame()
df_tax_braket['Salary'] = df_tax['Salary']
And assign each bracket a number 0 to n
df_tax_braket['Tax_Braket'] = df_tax['Salary'].rank().astype('int')
df_tax_braket.iloc[::4]
Now we can join this with df_employees using pd.merge_asof on column 'Salary'
df_employees = pd.merge_asof(df_employees.sort_values('Salary'),\
df_tax_braket,on='Salary')
df_employees.iloc[::4]
Second I took df_tax and added Tax_Braket as a column and dropped the Salary column.
df_tax['Tax_Braket'] = df_tax_braket['Tax_Braket']
df_tax = df_tax.drop('Salary',axis=1)
df_tax.head()
Finally we can merge df_tax with df_employees using the regular merge. We need to merge on two columns one is going to be Tax_Braket but the other ... well the other is not a column it's a list of columns... Fear not! We can restructure df_tax to make this work.
df_tax = df_tax.set_index('Tax_Braket').T.unstack().to_frame().reset_index()
df_tax.columns = ['Tax_Braket', 'Dep', 'Tax_Rate']
df_tax['Dep'] = df_tax['Dep'].astype('int')
df_tax.iloc[::12]
ok now we can merge on 'Tax_Braket' and 'Dep'
df_employees = pd.merge(df_employees,df_tax,on=['Tax_Braket', 'Dep'])
df_employees.iloc[::4]
Conclusion¶
So, there you have it... not as simple as in Excel, you're thinking? I would agree with you it is a little more work but once you understand it you can package these steps into a function to help abstract away the suffering.
A (maybe impossible) more efficient solution: the first thing that came to mind was to restructure df_tax as it is (before adding Tax_Rate) and merging with merge_asof on the Salary column and exact match merging on the Dep column all in one function call. I dont think it's possible as of v0.22 (please contact me if I'm wrong).